Notes from a Maintainer - Subhashish Panigrahi, OpenSpeaks
I document and archive languages spoken by South Asian communities.
I document and archive languages spoken by South Asian communities. In this region, we speak over 800 languages. Since most of the remaining languages are spoken rather than written, documenting them in audio and video formats is critical to their promotion and preservation. I am not a developer but a steward, and have been maintaining the FOSS required by many such languages.
There are two large areas where language technology support is poorer: script-related support for local languages with scripts, and support for the rest of the languages, since their issues are not well documented.
Emerging tools
OpenSpeaks Subtitler in action (Subhashish Panigrahi / CC BY-SA 4.0)
At OpenSpeaks, we maintain a small suite of open-source projects focused on multilingual audio-visual media, metadata, and documentation. These tools include: Subtitler (repo), an audio and video caption/subtitle editor; Tome (repo), a metadata editor; and Bento (repo), a media file and folder organiser, duration calculator, and media converter. These web apps are intended to work offline (with limited functionality) or over slow internet connections, allowing field documenters to use them on the go. Internally, we use many other open-source tools and utilities for automation, file management, and administrative purposes. Previously, we have created many other open-source tools, both at OpenSpeaks and at O Foundation, our parent organisation, mostly related to language technology.
Chapakala
Chapakala is an open-source Odia typeface revival project that Nasim Ali and I started in 2024. Chapakala19 revives a 19th-century workhorse typeface, and Chapakala 20 revives a similar 20th-century workhorse typeface. This is arguably the first full-fledged typeface revival project in Odia and will help reproduce old text, create new artistic and other designs, and improve optical character recognition (OCR) software. Tesseract, an open-source OCR engine, has not been trained for Odia since 2009 and has never been trained for letterpress-era fonts. Over 15,000 digitally archived books remain almost inaccessible due to a lack of OCR training.
Past projects
There are several open-source, open knowledge and open data projects I have built, co-created, largely contributed to, and maintained in the past. Some are not maintained or archived; some are maintained by others; some I continue to maintain; and some are included in larger projects. Some of these projects include:
Transliteration, Lekhani and OdiScript input methods
A handful of us were involved in reviving the nine-year-dormant Odia Wikipedia in early 2011. The earliest contributors, us, were not fluent in typing in InScript, an input method made by the Indian government. Enter transliteration, an intuitive near-phonetic input method. I worked closely with Junaid P.V., a developer and a Malayalam Wikimedian who had already mapped the Odia characters to Malayalam and many other Indian scripts. It was included in the Narayam input method extension in MediaWiki, the wiki software behind Wikipedia, among others, and later became a part of the official Wikimedia input methods called Universal Language Selector (ULS). As our contribution grew, we realised we were typing more and needed a phonetic keyboard optimised for Odia. I led the development of the Lekhani input method. It drew inspiration from Oriya phonetic typing in Ubuntu and the Oriya-QUERTY keyboard on macOS. Most of us switched to Lekhani immediately, and it remains the most widely used Odia input method on Wikimedia projects to date. I also worked on making Lekhani work on the now-defunct Firefox OS and macOS. The Indic Keyboard Android app also included Lekhani and Transliteration. Together with Manoj Sahukar, I also co-created OdiaScript, an Odia input method based on the popular Modular input method.
A FirefoxOS phone showing Lekhani input method (Photo: Subhashish Panigrahi / CC BY-SA 4.0)
{kind=link}
OpenSpeaks Data Pages
Speech synthesis has always fascinated me as a technology. During 2014-2015, I reviewed the quality of eSpeak, an open-source speech synthesiser for Odia, as part of a Centre for Internet and Society project. While eSpeak remains one of the oldest and most widely used text-to-speech systems for Indian languages, its synthesised voice sounds unnatural and is hard to use for long periods. Though it’s possible to build high-quality speech synthesis models with less data now, training speech synthesis models requires a lot of voice data. We also brought the Odia Wiktionary to life, a dictionary with meanings in many languages. Shitikantha Dash, a fellow Wikimedian, helped add over 100K headwords from the 1930–1941 lexicon Purnnachandra Ordia Bhashakosha. I started recording words to add pronunciations to Wiktionary and build a dataset for a future ASR project. Then, I started a project called Kathabhidhana based on a Python script written by Shrinivasan T. Later, open-source projects Lingua Libre, where I was a top contributor across all the languages supported at the time, and Mozilla Common Voice made this process easier. This project, with over 78,000 recordings, became the largest Odia voice dataset to be published with a Public Domain release. It was later archived in the Library of Congress’s permanent digital records while serving over 21,000 pages on Wiktionary.
Encoding converters in Odia
Legacy typefaces with ASCII or ISCII that predate the Unicode standard have long been used across Indian scripts, especially in the printing industry. Though Odia (then Oriya) was encoded in the Unicode standard in 1991, the publishing and broadcasting industries did not adopt Unicode-compliant typefaces for nearly three decades. In fact, many publishers continue to use legacy ASCII typefaces to date. The Wikipedia and Wikimedia communities struggled to extract text from content typed in such typefaces. Most Indian languages underwent a major shift, with digital and online content available in Unicode, while print and broadcast typesetting used fonts in legacy encodings. Companies that built fonts had their own proprietary encoding; sometimes, a single company made changes to the encoding with each release. So, encoding converters were built to ensure users could convert legacy text to Unicode.
Srujanika, a nonprofit based in Bhubaneswar, took the first step toward creating an Odia encoding converter. We, the Odia Wikimedia community, needed to access e-book and e-newspaper content. So, we built encoding converters and released them publicly as open source software. I was involved in co-creating (with Jnanaranjan Sahu, who built the most stable version of a converter, Manoj Sahukar, and Shitikantha Dash), testing, creating user guides, and promoting the converters publicly. As a result, we saw a significant increase in Unicode content first on social media, then on-wiki, and in many other places. I continue to maintain many of these converters. Most type foundries that the print industry relies on have released their own encoding converters.
Other tools
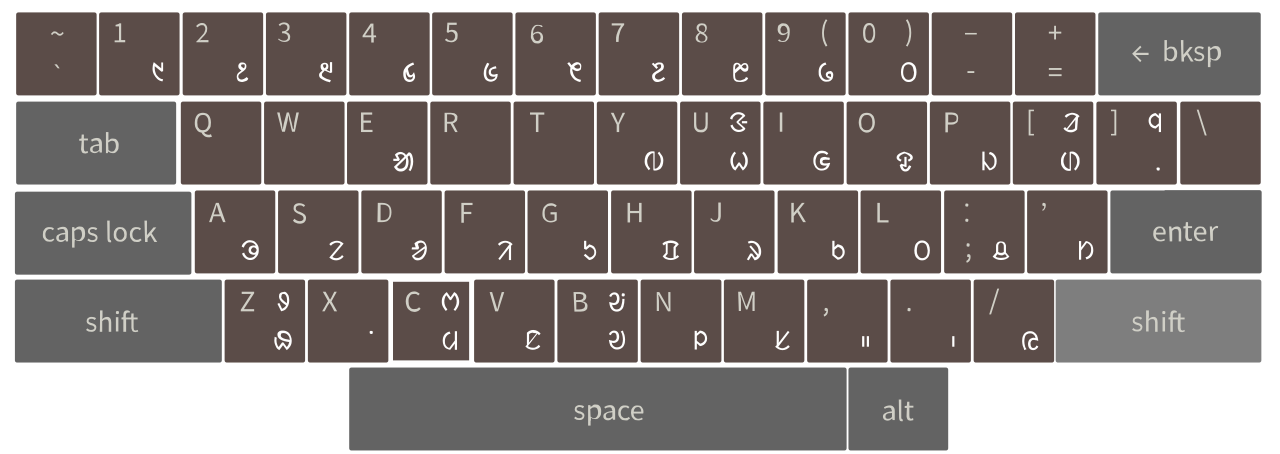
Ol Chiki (Santali-language script) keyboard layout for Sarjom Baha input method (Photo: Pooja Saxena and Subhashish Panigrahi / CC BY-SA 4.0)
{kind=link}
Project Ol Chiki: I developed and coordinated this project at Access to Knowledge (A2K), a programme at the Centre for Internet and Society. In collaboration with Santali-language experts Damayanti Beshra, Malati and Mangat Murmu, Kuanra Murmu and Raj Narayan Marndi, we created an open-source font (designed by Pooja Saxena) and an input method (developed by Jnanaranjan Sahu and Nasim Ali). I maintained the tools till the Santali Wikimedians took control of the project. Guru Gomke, the font and Sarjom Baha, the input method, continued to be widely used
Very helpful content! Sustainable packaging is becoming a priority for businesses, and choosing the right white paper bags and carry bag solutions can make a real difference. Thanks for sharing your expertise with the community.